Out-of-distribution (OOD) detection holds significant importance across many applications. While semantic and domain-shift OOD problems are well-studied, this work focuses on covariate shifts - subtle variations in the data distribution that can degrade machine learning performance. We hypothesize that detecting these subtle shifts can improve our understanding of in-distribution boundaries, ultimately improving OOD detection.
In adversarial discriminators trained with Batch Normalization (BN), real and adversarial samples form distinct domains with unique batch statistics — a property we exploit for OOD detection. We introduce DisCoPatch, an unsupervised Adversarial Variational Autoencoder (VAE) framework that harnesses this mechanism. During inference, batches consist of patches from the same image, ensuring a consistent data distribution that allows the model to rely on batch statistics. DisCoPatch uses the VAE's suboptimal outputs (generated and reconstructed) as negative samples to train the discriminator, thereby improving its ability to delineate the boundary between in-distribution samples and covariate shifts. By tightening this boundary, DisCoPatch achieves state-of-the-art results in public OOD detection benchmarks. The proposed model not only excels in detecting covariate shifts, achieving 95.5% AUROC on ImageNet-1K(-C), but also outperforms all prior methods on public Near-OOD (95.0%) benchmarks. With a compact model size of ≤25MB, it achieves high OOD detection performance at notably lower latency than existing methods, making it an efficient and practical solution for real-world OOD detection applications.
A prevalent generative-based approach for OOD detection involves utilizing the trained generator to evaluate the likelihood of unseen samples. However, in adversarial setups, some information about the ID boundary will be incorporated into the discriminator, as it learns to assess the probability of a sample being real (ID) or synthetic (OOD). In this work, we exploit the observation that BN can help an adversarially trained discriminator to separate underlying data distributions by recognizing that clean and adversarial images are drawn from two distinct domains (i.e. ID and OOD), in such way that that it can provide a boundary for the ID set. By adjusting where the discriminator learns to draw this boundary, we can create an OOD detector.
It is on this premise that we propose a Discriminative Covariate Shift Patch-based Network, DisCoPatch. DisCoPatch is an Adversarial VAE-inspired architecture, in which both the VAE and the discriminator are trained adversarially. DisCoPatch's approach combines generative and reconstruction-based strategies to distill information about the ID set and OOD boundaries to the discriminator during training in an unsupervised manner. Unlike traditional adversarial methods, DisCoPatch's focus is on leveraging the generator's output as a tool to refine the discriminator. DisCoPatch's discriminator only utilizes the current batch's (of patches) statistics in the BatchNorm2D layer.

DisCoPatch's approach combines generative and reconstruction-based strategies to distill information about the in-distribution set and out-of-distribution boundaries to the Discriminator.
The VAE is trained to reduce the ELBO while also producing samples that can fool the discriminator. The discriminator is trained on both reconstructed and generated patches to address specific challenges related to image fidelity and content representation. Reconstructions from VAEs typically lack detail, i.e., they have an insufficient high-frequency representation, which can be found in certain types of covariate shifts, such as blurriness. On the other hand, images generated from GANs often exhibit severe high-frequency differences, leading the discriminator to focus excessively on these components. This focus can hinder the generator's ability to capture low-frequency components. By training the discriminator on reconstructions and generations, and by encouraging both to appear more realistic, the discriminator's boundaries of the ID frequency spectrum become tighter, enhancing its ability to detect OOD samples.
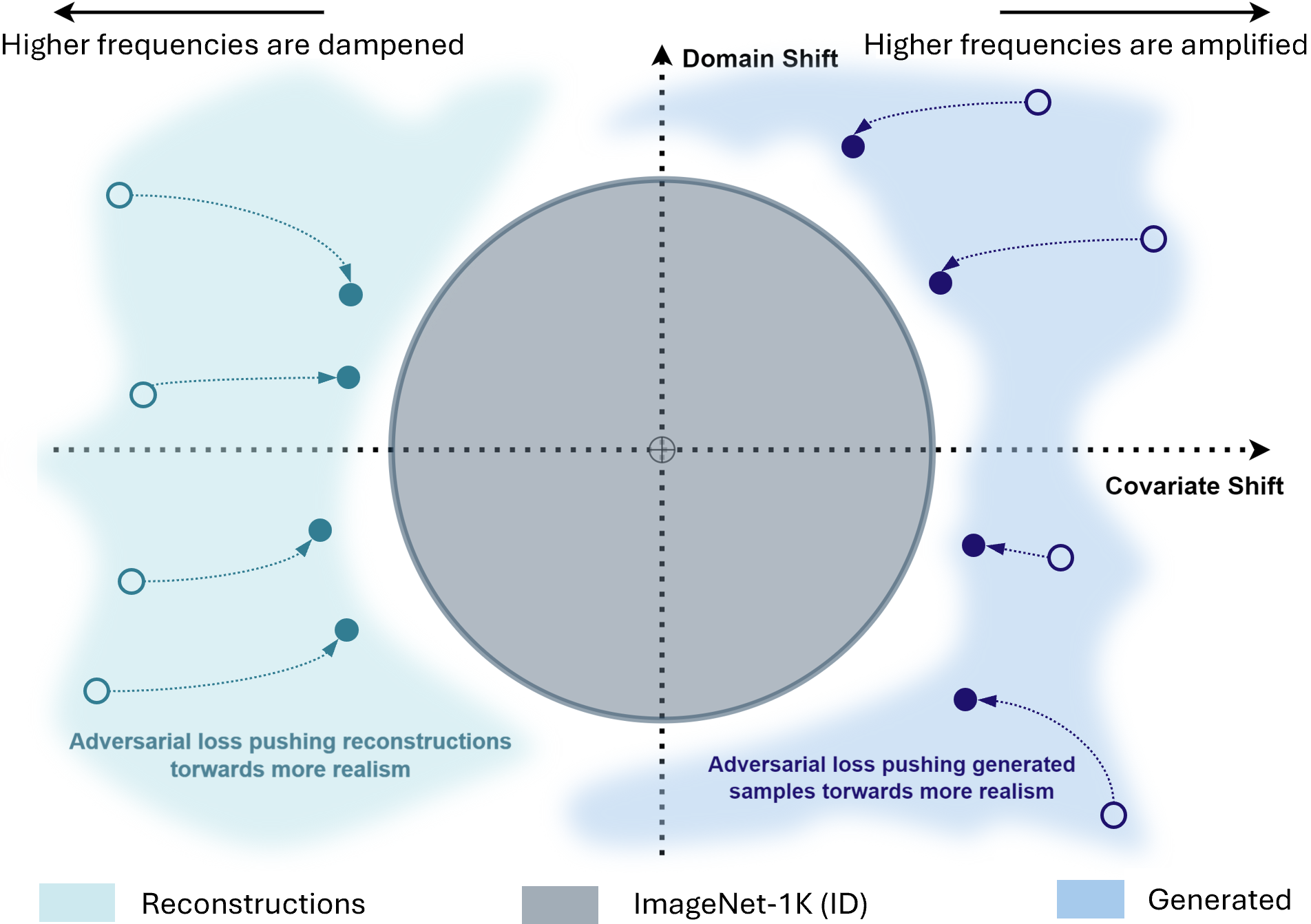
Covariate Shifts can be simulated by reconstructed and generated patches. Encouraging more realism helps to tighten the border between the ID set and the OOD sets.
The VAE in DisCoPatch's framework remains unchanged when compared to the traditional VAE, with parameters θ and composed of an encoder 𝓔 and a decoder 𝓖 responsible for generating an image output. The loss function of the VAE can be interpreted as a combination of a reconstruction term aimed at optimizing the performance of the encoding-decoding process, and a regularization term of the latent space, which ensures its regularization by aligning the encoder distributions with a standard normal distribution. This regularization term is represented by the Kullback-Leibler (KL) divergence between the produced distribution and a standard Gaussian distribution.
An additional model, parameterized by ϕ, is added to the traditional VAE architecture, the discriminator 𝓓. It has two main goals: first, it must discern between real images and images reconstructed by the VAE or generated from random noise; the discriminator's additional goal is to push not only the reconstructions toward more realism but also images sampled from random noise. Therefore, an adversarial loss term is imposed to encourage the VAE to generate or reconstruct images that fool the discriminator.
The final VAE loss function is thus a weighted combination of both the Vanilla VAE loss and the adversarial loss.
The patching strategy begins by taking a high-resolution input image, typically a standard 256x256 in resolution, which is cropped into N random patches of 64x64 each. This method enables the model to capture fine-grained details across various regions of the image. During training, batches consist of patches from multiple images, not just one. This setup helps accelerate training and ensures the model learns consistent ID features across different images, thus reducing the risk of overfitting to specific image characteristics.
During inference, batches are formed differently, with N patches taken from the same image. This ensures that the results are independent per image. The final anomaly score for an image is the average score of all its patches. The model is referred to as DisCoPatch-N, where N denotes the number of patches per image used during inference.
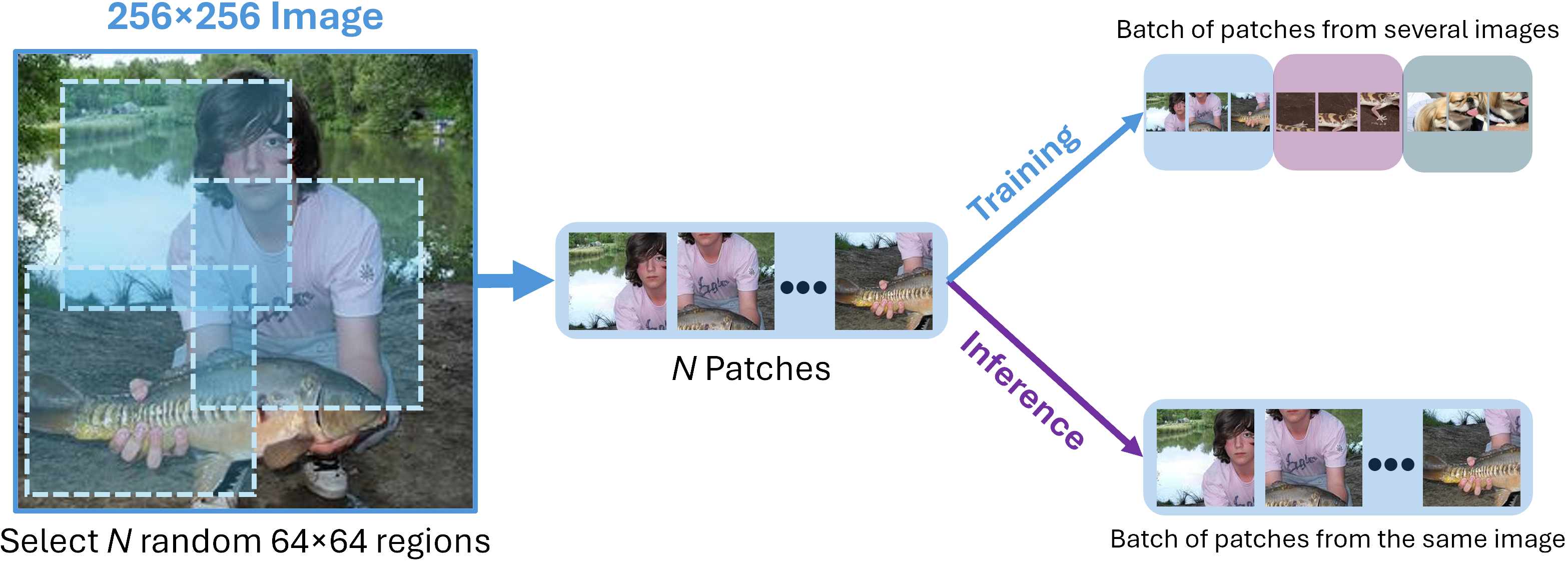
Different patching strategies employed by the model during training and inference.
DisCoPatch excels in Covariate Shift detection, achieving an AUROC of 95.5% on ImageNet-1K(-C) and outperforming all prior methods on Near-OOD detection with a score of 95.0%. Although the same does not occur for Far-OOD, DisCoPatch's performance is competitive, and the model is only beaten by far larger and slower models.
| OOD Type | OOD Dataset | AUROC | FPR@95 |
|---|---|---|---|
| Near-OOD | SSB-hard | 95.8% | 19.8% |
| NINCO | 94.3% | 39.0% | |
| Far-OOD | iNaturalist | 99.1% | 3.6% |
| DTD | 96.4% | 18.9% | |
| OpenImage-O | 94.4% | 29.7% | |
| Covariate Shift | ImageNet-1K(-C) | 97.2% | 10.6% |
Furthermore, DisCoPatch achieves these results with significantly lower latency (up to one order of magnitude) and a model size of less than 25MB, making it a viable option for real-time applications with limited resources.
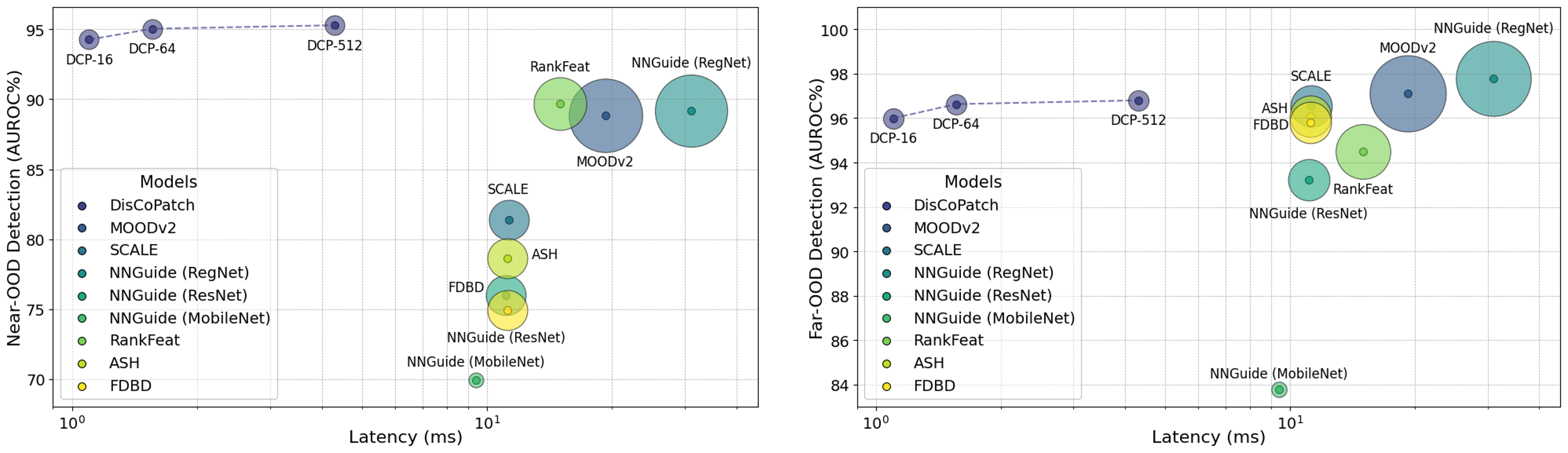
Near-OOD and Far-OOD detection performance vs. latency of the models. Circumference size is equivalent to relative model size.
@inproceedings{caetano2025discopatch,
title={DisCoPatch: Taming Adversarially-driven Batch Statistics for Improved Out-of-Distribution Detection},
author={Caetano, Francisco and Viviers, Christiaan and Zavala-Mondrag{\'o}n, Luis A and van der Sommen, Fons and others},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={2898--2908},
year={2025}
}