Synthetic medical data offers a scalable solution for training robust models, but significant domain gaps limit its generalizability to real-world clinical settings. This paper addresses the challenge of cross-domain translation between synthetic and real X-ray images of the head, focusing on bridging discrepancies in attenuation behavior, noise characteristics, and soft tissue representation. We propose MedShift, a unified class-conditional generative model based on Flow Matching and Schrödinger Bridges, which enables high-fidelity, unpaired image translation across multiple domains.
Unlike prior approaches that require domain-specific training or rely on paired data, MedShift learns a shared domain-agnostic latent space and supports seamless translation between any pair of domains seen during training. We introduce X-DigiSkull, a new dataset comprising aligned synthetic and real skull X-rays under varying radiation doses, to benchmark domain translation models. Experimental results demonstrate that, despite its smaller model size compared to diffusion-based approaches, MedShift offers strong performance and remains flexible at inference time, as it can be tuned to prioritize either perceptual fidelity or structural consistency, making it a scalable and generalizable solution for domain adaptation in medical imaging. The code and dataset will be publicly released.
The X-DigiSkull dataset is introduced to support domain adaptation research in X-ray imaging. It includes synthetic skull X-rays generated via the Mentice VIST® simulator and real scans acquired from a physical skull phantom using the Philips Azurion Image Guided Therapy (IGT) system.
Images cover standard neuro-intervention viewpoints and are provided at three radiation dose levels: low, normal, and exposure (a Philips-exclusive mode offering enhanced detail). Synthetic images are rendered to approximate the real views, aiming to preserve spatial consistency rather than enable direct supervision. All images are cropped and resized to 780×780 pixels.
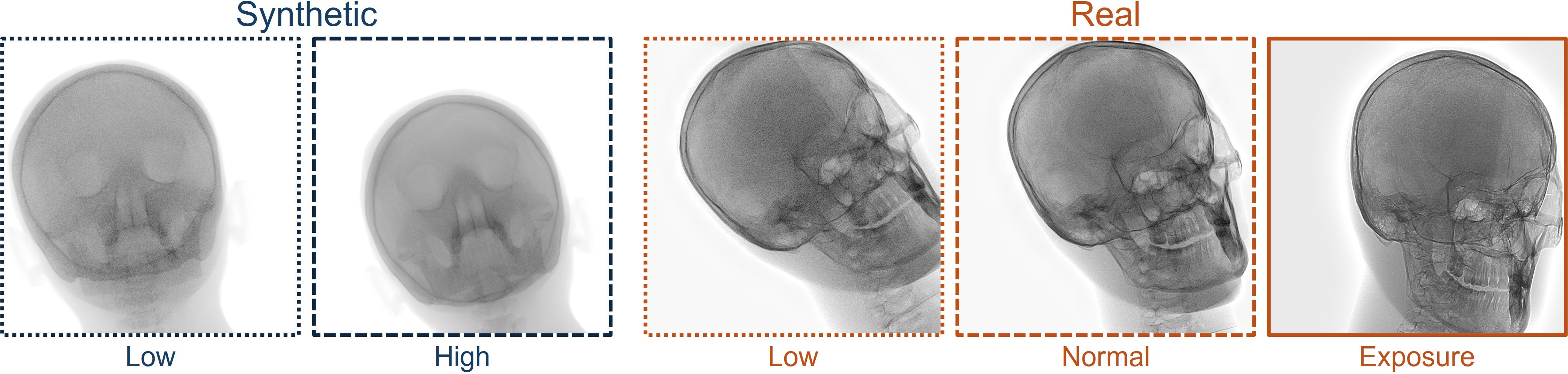
The synthetic domain contains Low and High dosage samples generated using the Mentice VIST® simulator; the real domain includes Low, Normal, and Exposure dosage categories acquired using the Philips Azurion IGT system.
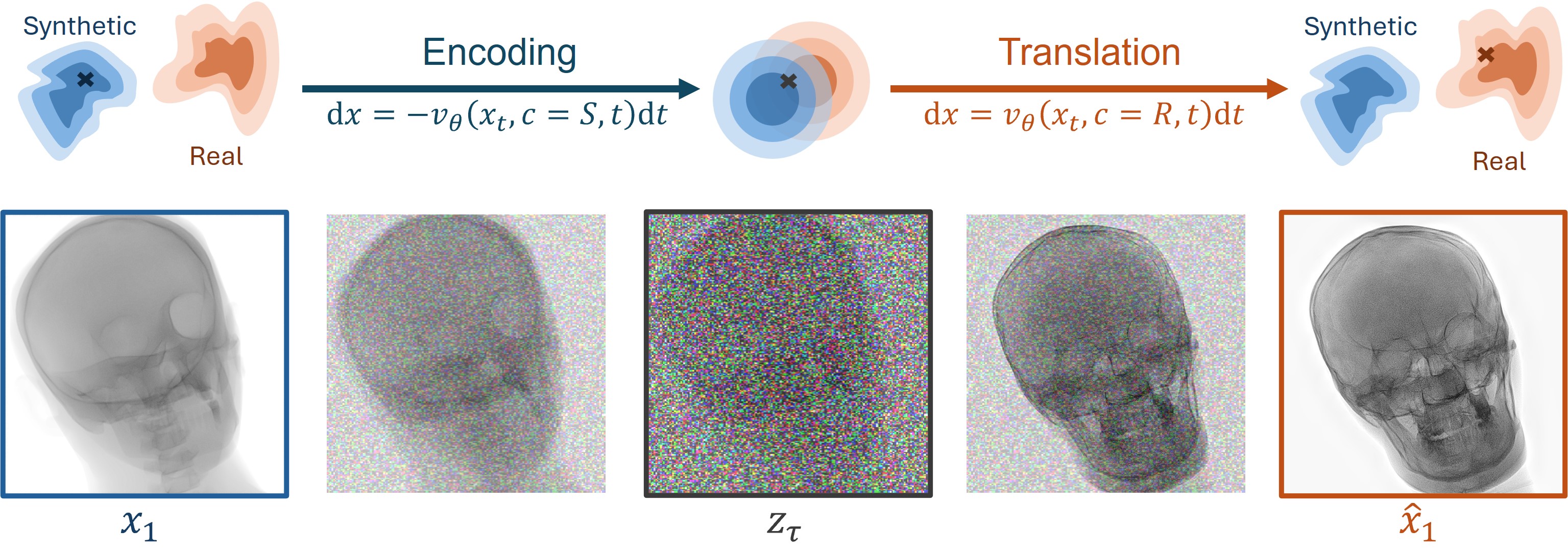
MedShift is a class‑conditional Flow Matching model for translating high‑resolution X‑ray images between domains, such as synthetic and real. It is trained with classifier‑free guidance (CFG), which lets it learn how to map between domains without paired training data. By working in a latent space learned from a pretrained VAE, MedShift preserves anatomical detail while reducing computation.
In practice, MedShift works in two steps. First, it encodes the input image into a shared, domain‑agnostic latent representation. Then, it translates that representation into the target domain, adjusting style and appearance while preserving the underlying anatomy.
This approach enables flexible, high‑fidelity domain transfer between any domains seen during training, making it suitable for applications such as adapting simulated medical images to real‑world settings.
The results highlight the trade-off between realism and anatomical preservation in cross-domain X-ray image translation. Models that excel in visual realism, such as CycleGAN‑Turbo, tend to introduce spurious structures that compromise anatomical accuracy. In contrast, methods like Hierarchy Flow prioritize structure but offer limited style transfer. MedShift aims to achieve both high realism and strong structural fidelity, with additional benefits in memory efficiency and training speed.
| Type | Method | CFID ↓ | Cov. ↑ | CMMD ↓ | Rank ↓ | LPIPS ↓ | SSIM ↑ | Rank ↓ | Avg. Rank ↓ |
|---|---|---|---|---|---|---|---|---|---|
| None | Synthetic Images | 262.56 | 0.48 | 10.46 | -- | 0.00 | 1.00 | -- | -- |
| NF | Hierarchy Flow (st=0.1) | 260.75 | 0.47 | 10.62 | 13 | 0.01 | 0.99 | 1 | 7 |
| Hierarchy Flow (st=0.25) | 253.59 | 0.50 | 10.64 | 12 | 0.01 | 0.99 | 1 | 6.5 | |
| Hierarchy Flow (st=0.4) | 253.09 | 0.55 | 12.02 | 11 | 0.40 | 0.58 | 11 | 11 | |
| GAN | CycleGAN-Turbo (ss=0.0) | 161.11 | 0.85 | 5.68 | 3 | 0.47 | 0.70 | 10 | 6.5 |
| CycleGAN-Turbo (ss=0.5) | 154.66 | 0.81 | 1.89 | 2 | 0.52 | 0.55 | 13 | 7.5 | |
| CycleGAN-Turbo (ss=1.0) | 147.39 | 0.86 | 2.51 | 1 | 0.51 | 0.56 | 12 | 6.5 | |
| DDPM | Z-STAR | 205.26 | 0.60 | 9.41 | 10 | 0.13 | 0.90 | 4 | 7 |
| SDEdit (st=0.1) | 204.27 | 0.65 | 7.18 | 9 | 0.12 | 0.89 | 5 | 7 | |
| SDEdit (st=0.2) | 196.06 | 0.70 | 7.47 | 7 | 0.17 | 0.83 | 7 | 7 | |
| SDEdit (st=0.3) | 190.12 | 0.71 | 7.89 | 5 | 0.21 | 0.78 | 8 | 6.5 | |
| FM | MedShift (τ=0.6) | 201.72 | 0.65 | 8.10 | 8 | 0.09 | 0.91 | 3 | 5.5 |
| MedShift (τ=0.45) | 195.17 | 0.72 | 8.17 | 6 | 0.14 | 0.85 | 6 | 6 | |
| MedShift (τ=0.3) | 171.59 | 0.71 | 8.14 | 4 | 0.24 | 0.75 | 9 | 6.5 |
CycleGAN‑Turbo achieves the strongest results in distributional metrics such as CFID and coverage, but often introduces anatomical artifacts and spurious features. Hierarchy Flow preserves structure exceptionally well but applies minimal transformation, resulting in poor domain adaptation and failure at high style strengths.
Other diffusion-based models show limitations: Z‑STAR struggles to transfer style completely, while SDEdit introduces artifacts in cranial areas. Overall, MedShift achieves the most balanced trade-off across all τ settings, leading in average ranking.
MedShift is also more memory‑efficient than Stable Diffusion U‑Net variants, using a smaller custom U‑Net that speeds up training and reduces resource usage.
The following interactive slider allows direct comparison between the original input image and the MedShift-translated output. Drag the handle left or right to reveal more of either image.
@inproceedings{caetano2025medshift,
title={MedShift: Implicit Conditional Transport for X-Ray Domain Adaptation},
author={Caetano, Francisco and Viviers, Christiaan and van der Sommen, Fons and others},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5499--5508},
year={2025}
}