Flow Matching has emerged as a powerful framework for learning continuous transformations between distributions, enabling high-fidelity generative modeling. This work introduces Symmetrical Flow Matching~(SymmFlow), a new formulation that unifies semantic segmentation, classification, and image generation within a single model.
Using a symmetric learning objective, SymmFlow models forward and reverse transformations jointly, ensuring bi-directional consistency, while preserving sufficient entropy for generative diversity. A new training objective is introduced to explicitly retain semantic information across flows, featuring efficient sampling while preserving semantic structure, allowing for one-step segmentation and classification without iterative refinement. Unlike previous approaches that impose strict one-to-one mapping between masks and images, SymmFlow generalizes to flexible conditioning, supporting both pixel-level and image-level class labels.
Experimental results on various benchmarks demonstrate that SymmFlow achieves state-of-the-art performance on semantic image synthesis, obtaining FID scores of 11.9 on CelebAMask-HQ and 7.0 on COCO-Stuff with only 25 inference steps. Additionally, it delivers competitive results on semantic segmentation and shows promising capabilities in classification tasks.
Symmetrical Flow Matching treats semantic understanding and image synthesis as two sides of the same continuous transformation. Given an image distribution X and a semantic representation Y (dense masks or global labels), SymmFlow learns bi-directional flows that map noise to images while simultaneously transporting labels toward noise and back. This unifies semantic segmentation, classification, and semantic image generation in a single model, instead of training separate networks for each task.
The key idea is to preserve entropy in the image path (to keep generation diverse) while enforcing semantic consistency in the label path. This is achieved by a symmetric objective that couples the two flows and forces the model to retain task-relevant information in both directions.

SymmFlow jointly models semantic segmentation and generation as opposing flows. Noise transitions into an image while a label evolves into noise and vice versa.
SymmFlow learns a joint velocity field over images and semantic representations. For each sample, a time variable \( t \sim \mathcal{U}(0, 1) \) is drawn. The image branch interpolates between Gaussian noise and the data point, while the semantic branch interpolates between the label and Gaussian noise:
\[ \begin{cases} x_t = (1 - t)\,\xi_x + t\,x, \\ y_t = (1 - t)\,y + t\,\xi_y, \end{cases} \]
where \(\xi_x\) and \(\xi_y\) are independent Gaussian noise terms. The corresponding optimal transport velocities simply reverse these interpolations:
\[ \begin{cases} v_x = x - \xi_x, \\ v_y = \xi_y - y, \\ v = (v_x, v_y). \end{cases} \]
A single neural network \( v_{\theta}(x_t, y_t, t) \) jointly predicts the concatenated velocity vector \( v \) and is trained with a squared-error Flow Matching loss:
\[ \mathcal{L} = \mathbb{E}_{x, y, t} \bigl[ || v_{\theta}(x_t, y_t, t) - v || ^2 \bigr]. \]
This symmetric formulation enforces consistency between the image and label trajectories: good image generation requires preserving semantic information, and good semantic predictions require coherent image trajectories.
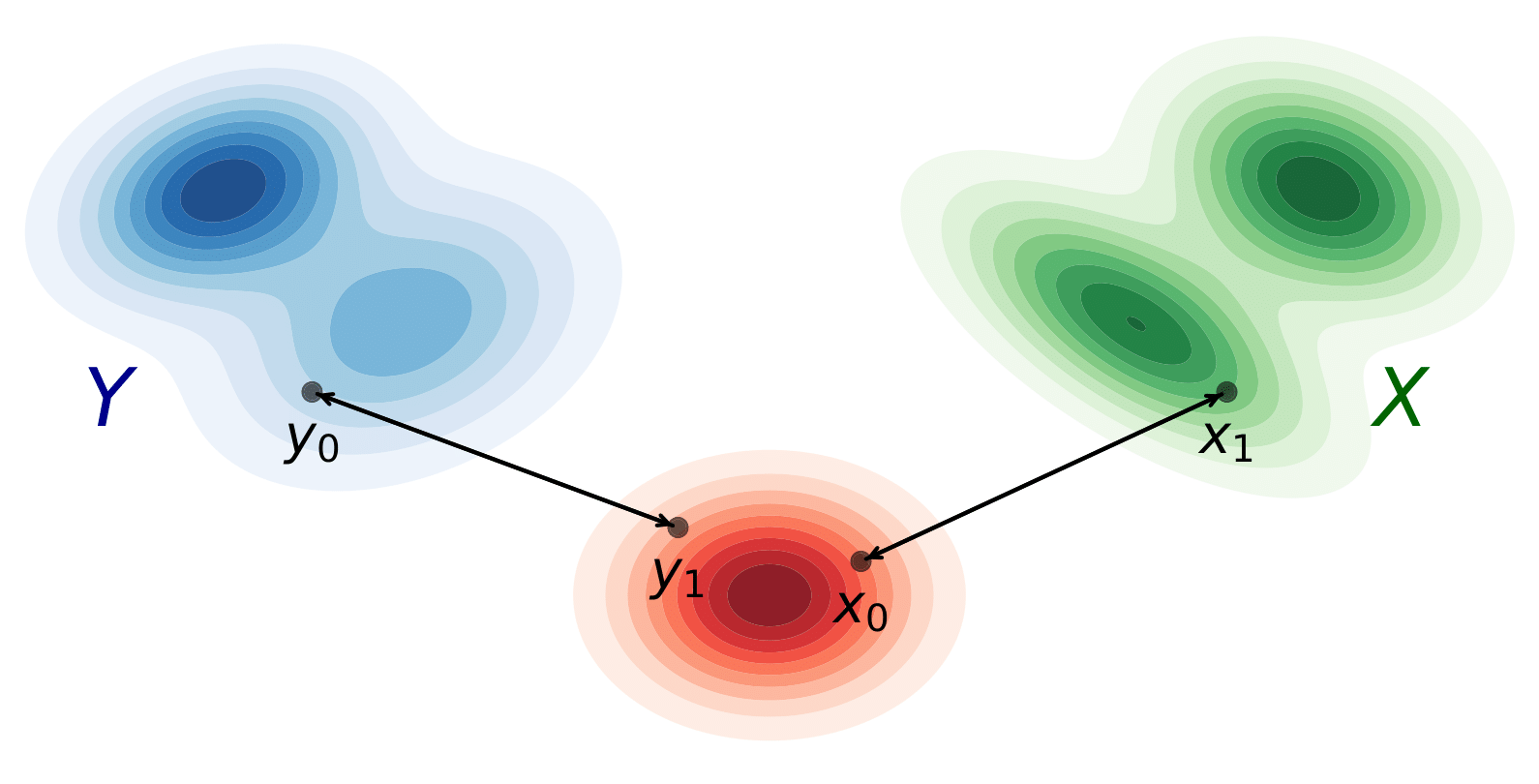
Illustration of optimal transport between the data distributions X and Y and an intermediate Gaussian distribution, as modeled by SymmFlow.
Conventional generative classifiers based on diffusion models estimate class posteriors by evaluating per-class likelihoods or ELBOs, requiring thousands of denoising steps across all possible labels. In contrast, SymmFlow directly integrates the learned velocity field for the semantic branch:
\[ y_{0} = y_{1} + \int_{1}^{0} v_{\theta}(x_{t}, y_{t}, t)_{y}\, \mathrm{d}t, \]
where \(v_{\theta}(\cdot)_{y}\) denotes the semantic component of the velocity field. A standard ODE solver (Euler in our experiments) is used with a small number of steps, allowing the model to recover class logits or segmentation masks in a single forward trajectory.
For classification, SymmFlow predicts a continuous semantic value that is mapped to the nearest class label. For semantic segmentation, each pixel’s predicted RGB vector is mapped to the nearest predefined class-specific RGB code, enabling dense predictions. Crucially, both operations reuse the same model that is used for generation.
Semantic labels are low-entropy and discrete, which can destabilize flow-based training. To avoid degenerate solutions, SymmFlow dequantizes labels into a continuous space. Given a discrete label tensor \(Y\), the dequantized representation is defined as:
\[ Y' = Y + \varepsilon, \qquad \varepsilon \sim \mathcal{U}(-\beta, +\beta), \]
where \(\beta\) controls the noise amplitude so that semantics remain well-defined while increasing entropy. For classification, label indices are first normalized to \([-1, +1]\) and then dequantized, providing a continuous, structured conditioning signal. This simple mechanism significantly stabilizes training and improves reverse-flow predictions.
For high-resolution semantic image synthesis on CelebAMask-HQ and COCO-Stuff, SymmFlow operates in the latent space of a pre-trained Stable Diffusion VAE. The U-Net backbone from Stable Diffusion 2.1 is adopted, and the first and last convolutional layers are widened to accommodate concatenated image and semantic channels.
Sampling is performed with an Euler ODE solver using only 25 steps, a substantial reduction compared to the 200–1000 denoising steps typical in diffusion-based semantic image synthesis. This yields a favorable trade-off between image quality, segmentation accuracy, and inference latency.

Non-curated samples from SymmFlow on CelebAMask-HQ (left) and COCO-Stuff (right). Top: semantic masks. Bottom: generated images after 25 integration steps. The model produces mask-consistent, high-fidelity samples with strong structural alignment to the conditioning.

Non-curated segmentation masks generated by the model trained on CelebAMask-HQ (left) and COCO-Stuff (right). The top row shows the ground-truth segmentation mask. The middle row shows the image used to condition the model. The bottom row shows the segmentations after 25 integration steps with the Euler ODE solver.
SymmFlow is evaluated on semantic segmentation and semantic image synthesis across CelebAMask-HQ and COCO-Stuff, compared against specialized segmentation models and state-of-the-art diffusion-based conditional generators. SymmFlow outperforms semantic image synthesis baselines in FID while remaining competitive with specialized segmentation models.
| Category | Method | Steps | SS (mIoU ↑) | SIS (FID ↓ / LPIPS ↑) | ||
|---|---|---|---|---|---|---|
| CelebAMask-HQ | COCO-Stuff | CelebAMask-HQ | COCO-Stuff | |||
| SS | DML-CSR | 1 | 77.8 | — | × | × |
| SegFace | 1 | 81.6 | — | × | × | |
| DeeplabV2 | 1 | — | 33.2 | × | × | |
| MaskFormer | 1 | — | 37.1 | × | × | |
| SegFormer | 1 | — | 46.7 | × | × | |
| SIS | pix2pixHD | 1 | × | × | 54.7 / 0.529 | 111.5 / — |
| SPADE | 1 | × | × | 42.2 / 0.487 | 33.9 / — | |
| SC-GAN | 1 | × | × | 19.2 / 0.395 | 18.1 / — | |
| BBDM | 200 | × | × | 21.4 / 0.370 | — | |
| ControlNet | 20 | × | × | 24.0 / 0.528 | 36.6 / 0.671 | |
| SDM | 1000 | × | × | 18.8 / 0.422 | 15.9 / 0.518 | |
| SCDM | 250 | × | × | 17.4 / 0.418 | 15.3 / 0.519 | |
| SCP-Diff | 800 | × | × | — | 11.3 / — | |
| Both | SemFlow | 25 | 69.4* | 35.7* | 32.6 / 0.393 | 90.0* / 0.685* |
| SymmFlow (Proposed) | 25 | 69.3 | 39.6 | 11.9 / 0.464 | 7.0 / 0.609 | |
@article{caetano2025symmetrical,
title={Symmetrical Flow Matching: Unified Image Generation, Segmentation, and Classification with Score-Based Generative Models},
author={Caetano, Francisco and Viviers, Christiaan and De With, Peter HN and van der Sommen, Fons},
journal={arXiv preprint arXiv:2506.10634},
year={2025}
}